



Evaluating Voice Conversion based Privacy Protection against Informed Attackers
Brij Mohan Lal Srivastava, Nathalie Vauquier, Md Sahidullah, Aurélien Bellet, Marc Tommasi and Emmanuel Vincent

Context
- Distinguishable and Repeatable biometric references can be extracted from speech
- Speech processing raises privacy threats
- Anonymization ensures that original speaker cannot be linked to the published anonymized dataset
- The anonymized data must be fit for use in downstream tasks
Contributions
- Compare 3 anonymization methods based on voice conversion
- Definition of target voice selection strategies
- Characterization of attacker’s knowledge about the anonymization scheme
- Evaluation of privacy and utility
Threat model
- The speaker publishes the speech data after anonymization
- The user tries to use the anonymized public data for downstream tasks
- The attacker tries to discover the identity of the speaker in the public data




Voice conversion based anonymization
Voice conversion
- Logical speaker anonymization framework
- Convert source speaker’s voice to a target speaker
- Conversion may not be perfect, residual source speaker info might be present
- Choice of target speaker is critical for strength of anonymization
- Allows data publication
- First proposed in 2009 [2], many techniques proposed thereafter
VC methods: criteria
VC methods are selected based on the following criteria:
- Non-parallel
- Many-to-many
- Source/language independent
Three VC methods
- VoiceMask: simple frequency warping based on composition of two functions $B$ and $Q$: $ f’ = B(Q(f, \alpha), \beta) $
- Vocal Tract Length Normalization: learn transformation parameters between source and target class spectra
- Disentangled Speech Representation: separate encoders for content (instance normalization) and speaker (average pooling) information
Anonymization Model
Anonymization framework
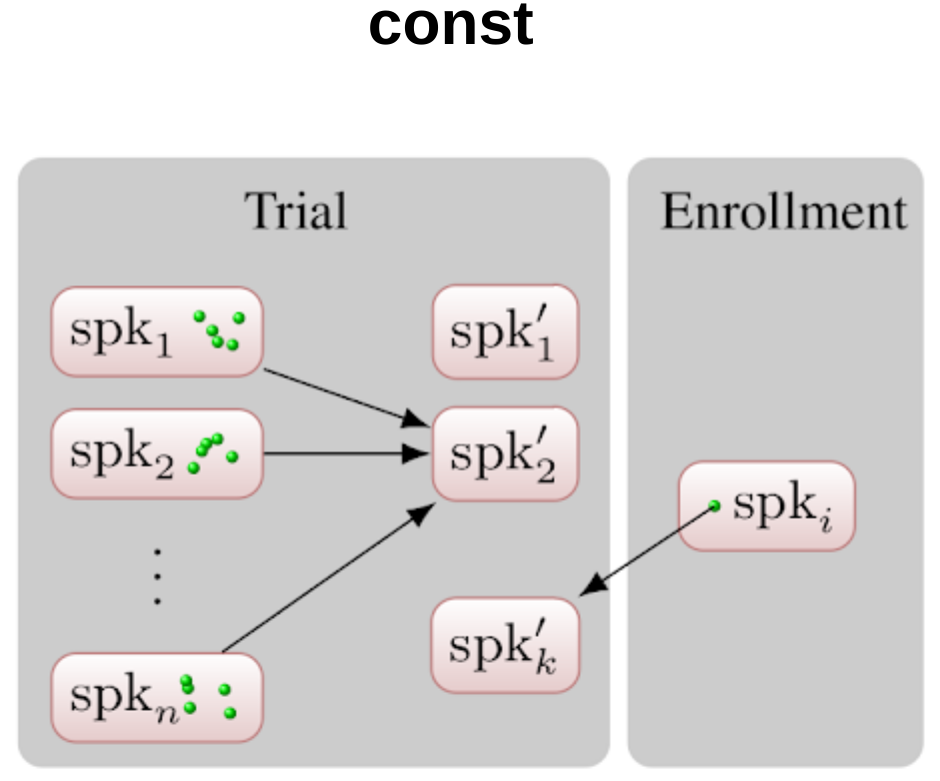
The target can be a single speaker from the pool or an average of many speakers.

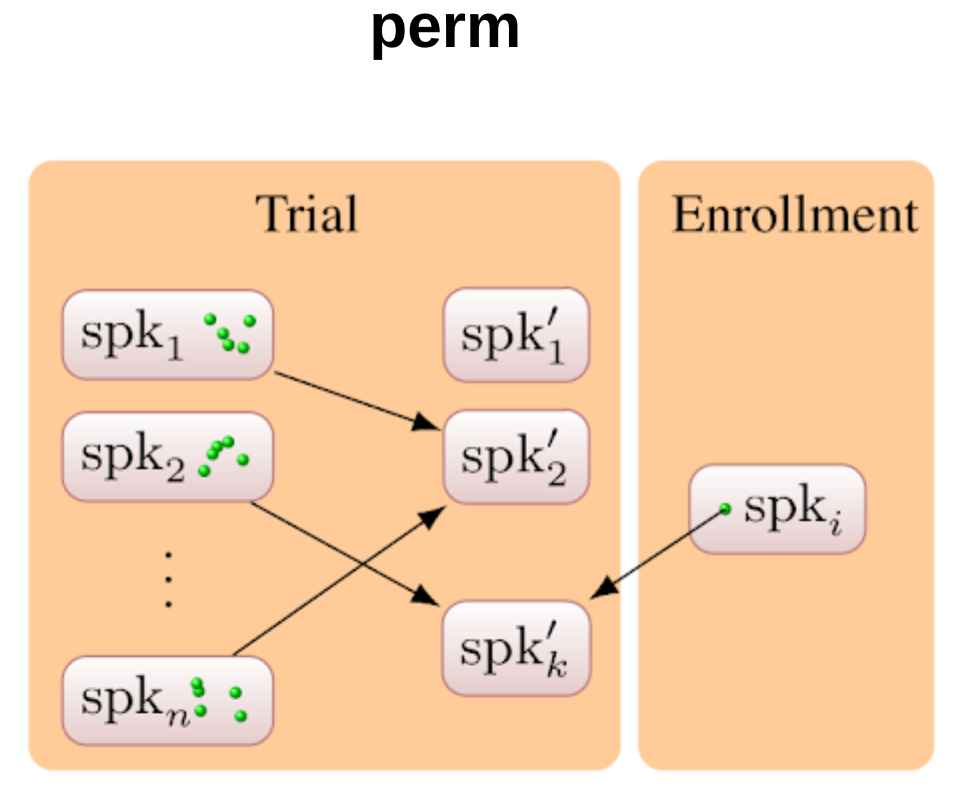
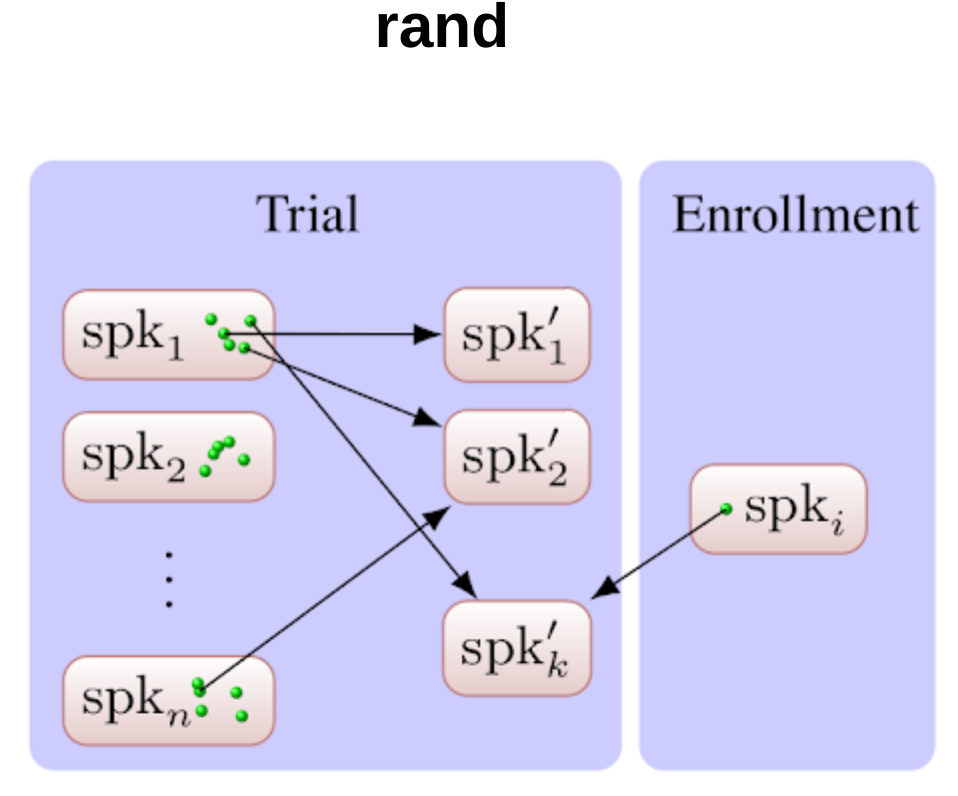
Target selection strategies
Design of Attackers
Ignorant attacker

Semi-Informed attacker

Informed attacker

Experiments
Training data
All the data subsets are derived from LibriSpeech corpus.
| Component | Dataset | Training |
|---|---|---|
| VoiceMask | None | No training required, ($\alpha$, $\beta$ are selected randomly from a predefined range) |
| Disentangled VC | LibriTTS 100h | (Content, Speaker) encoders are trained end-to-end to reconstruct the speech waveform |
| VTLN | LibriSpeech 460h | K-means clusters (8 centroids) and transformation paramters are learnt |
| Attackers | Anonymized training data to induce "knowledge" of anonymization | |
| ASR for evaluation | End-to-End (CTC + Attention) ASR is trained | |
Evaluation data
| Male | Female | |
|---|---|---|
| #Speakers | 13 | 16 |
| Genuine trials | 449 | 548 |
| Impostor trials | 9457 | 11,196 |
Evaluation protocol
- Attackers are simulated using speaker verification, which produce PLDA scores
- Measure of privacy: Equal Error Rate (EER) computed using PLDA scores
- Measure of utility: Word Error Rate (WER)
Results
Results on privacy (EER)




- Reasonable privacy protection can be provided in Semi-Informed case
- perm strategy outperforms the rest
- Informed attacker shows speaker information can be discovered, but not realistic
PLDA score distribution
- More overlap between the score distributions ensures more privacy
- Overlap decreases as we move from Ignorant to Informed attacker

Results on utility (WER)
- With rise in WER, utility decreases for all VC algorithms
- VoiceMask and VTLN produce reasonable loss of utility

Conclusion
- Investigated VC algorithms for speaker anonymization
- Target selection and attacker’s knowledge are critical for strength of anonymization
- Simple methods can provide reasonable protection