Privacy in Speech Processing
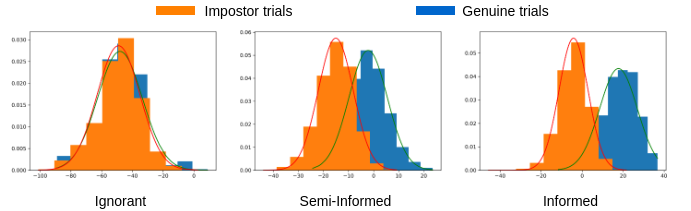 Unlinkability through PLDA scores
Unlinkability through PLDA scores
Abstract
Speech signals are a rich source of speaker-related information including sensitive attributes like gender, identity, accent, pathological conditions, etc. With a small amount of found speech data, such attributes can be extracted and modeled for malicious purposes like voice cloning and spoofing. Despite speech data being sensitive in nature, automatic speech recognition (ASR) is a key technology in many services and applications. This typically requires user devices to send their speech data to the cloud for ASR decoding. As the speech signal carries a lot of information about the speaker, this raises serious privacy concerns.
The main focus of my PhD is to investigate anonymization techniques which can effectively remove sensitive attributes from speech signal while preserving the linguistic content for utility. In this talk I will describe two different approaches for achieving speaker anonymization. The first is based on adversarial representation learning wherein we anonymize the hidden representation of ASR so that it cannot be used for identifying speakers. The second approach is based on voice conversion which aims to transform the original voice into that of an imaginary speaker. I will present the results of these two approaches and conclude with remarks on future directions.
Brij Mohan Lal Srivastava
Co-founder and CEO of Nijta
I am building a privacy-enabled voice analytics platform.