Biography
Latest: With the support of Inria and Euratechnologies, I have decided to take voice anonymization to society at large in the form of Nijta, a deeptech startup based in Lille. If you are interested to know more and try the solutions provided by Nijta, send me an email at the address given at the end of this page, and I promise to contact you soon.
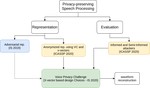
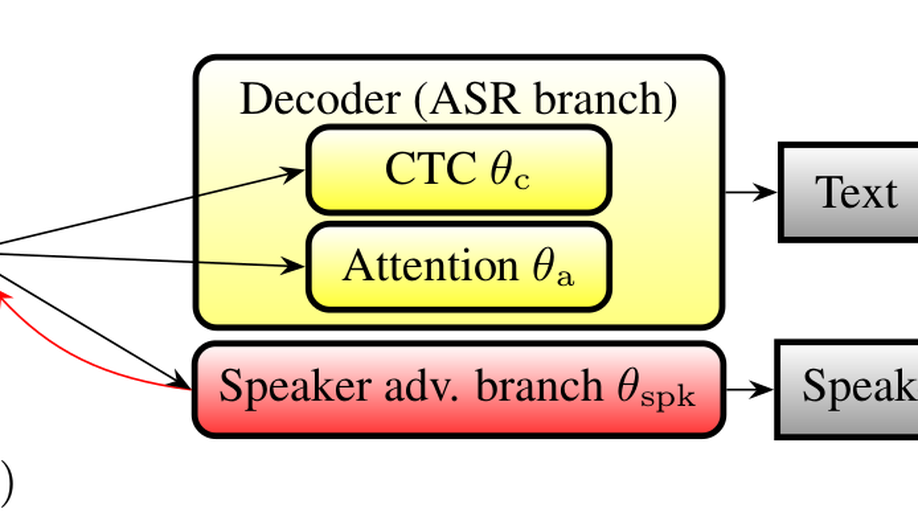
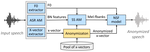
I recently finished my PhD at Inria where I worked in the Magnet and the Multispeech teams. I was supervised by Dr. Aurélien Bellet, Dr. Emmanuel Vincent and Prof. Marc Tommasi. My work mainly focused towards privacy-preserving speech processing.
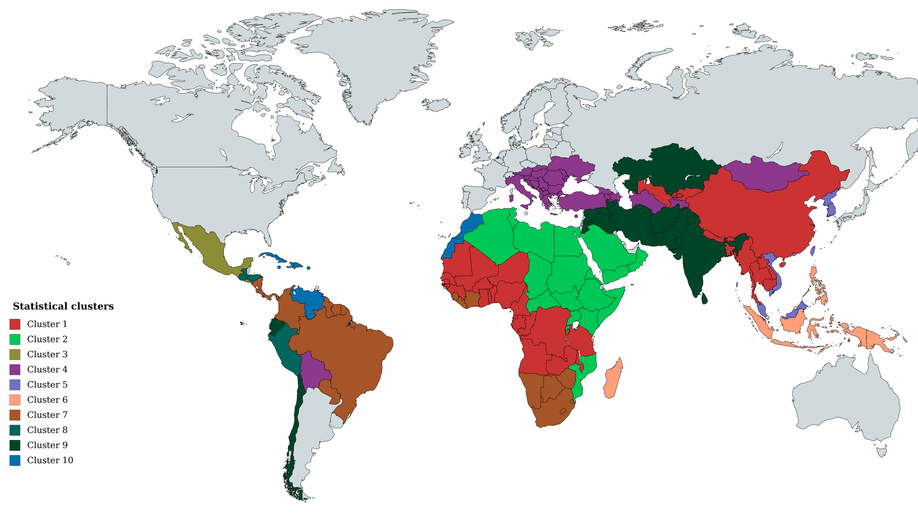
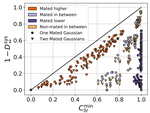
Check out the Voice Privacy Challenge to know more about the privacy benchmarks we obtained using our baseline and participate to evaluate your own anonymization methods.
Interests
- Speech & Language Processing
- Neural Networks
- Privacy
Education
-
PhD in Computer Science, 2018 - 2021
Inria (Université de Lille)
-
MS by Research in Computer Science, 2014 - 2017
International Institute of Information Technology (IIIT), Hyderabad
-
BTech in Information Technology, 2007 - 2011
SASTRA University